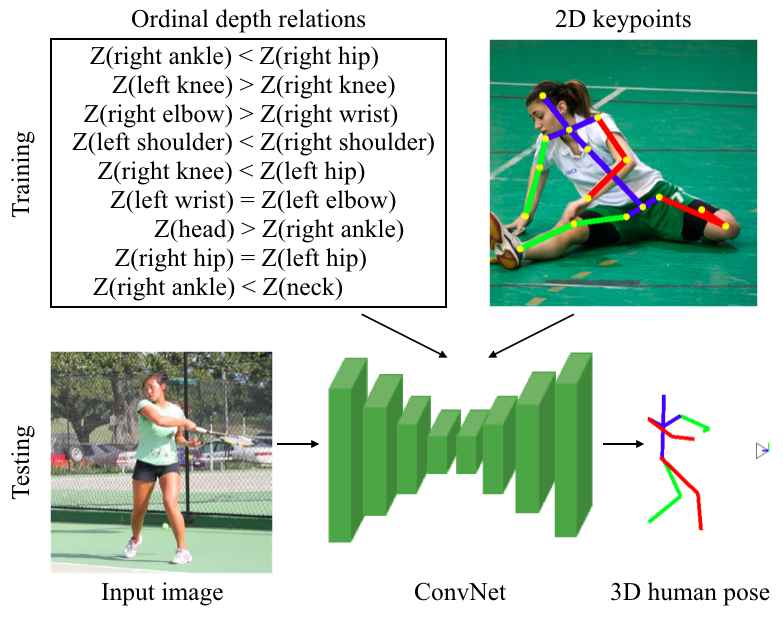
Our ability to train end-to-end systems for 3D human pose estimation from single images is currently constrained by the limited availability of 3D annotations for natural images. Most datasets are captured using Motion Capture (MoCap) systems in a studio setting and it is difficult to reach the variability of 2D human pose datasets, like MPII or LSP. To alleviate the need for accurate 3D ground truth, we propose to use a weaker supervision signal provided by the ordinal depths of human joints. This information can be acquired by human annotators for a wide range of images and poses. We showcase the effectiveness and flexibility of training Convolutional Networks (ConvNets) with these ordinal relations in different settings, always achieving competitive performance with ConvNets trained with accurate 3D joint coordinates. Additionally, to demonstrate the potential of the approach, we augment the popular LSP and MPII datasets with ordinal depth annotations. This extension allows us to present quantitative and qualitative evaluation in non-studio conditions. Simultaneously, these ordinal annotations can be easily incorporated in the training procedure of typical ConvNets for 3D human pose. Through this inclusion we achieve new state-of-the-art performance for the relevant benchmarks and validate the effectiveness of ordinal depth supervision for 3D human pose.
Georgios Pavlakos,
Xiaowei Zhou,
Kostas Daniilidis
Computer Vision and Pattern Recognition (CVPR), 2018 (Oral Presentation)
project page
/
supplementary
/
video
/
code
/
data
/
bibtex
@inproceedings{pavlakos2018ordinal,
Author = {Pavlakos, Georgios and Zhou, Xiaowei and Daniilidis, Kostas},
Title = {Ordinal Depth Supervision for 3{D} Human Pose Estimation},
Booktitle = {CVPR},
Year = {2018}}
For any questions regarding this work, please contact the corresponding author at pavlakos@seas.upenn.edu