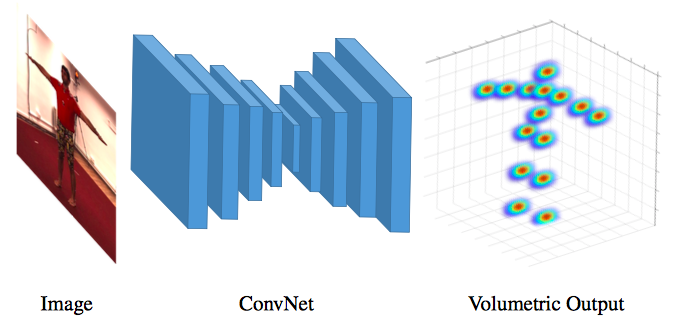
This paper addresses the challenge of 3D human pose estimation from a single color image. Despite the general success of the end-to-end learning paradigm, top performing approaches employ a two-step solution consisting of a Convolutional Network (ConvNet) for 2D joint localization and a subsequent optimization step to recover 3D pose. In this paper, we identify the representation of 3D pose as a critical issue with current ConvNet approaches and make two important contributions towards validating the value of end-to-end learning for this task. First, we propose a fine discretization of the 3D space around the subject and train a ConvNet to predict per voxel likelihoods for each joint. This creates a natural representation for 3D pose and greatly improves performance over the direct regression of joint coordinates. Second, to further improve upon initial estimates, we employ a coarse-to-fine prediction scheme. This step addresses the large dimensionality increase and enables iterative refinement and repeated processing of the image features. The proposed approach outperforms all state-of-the-art methods on standard benchmarks achieving a relative error reduction greater than 30% on average. Additionally, we investigate using our volumetric representation in a related architecture which is suboptimal compared to our endto-end approach, but is of practical interest, since it enables training when no image with corresponding 3D groundtruth is available, and allows us to present compelling results for in-the-wild images
Georgios Pavlakos,
Xiaowei Zhou,
Konstantinos G. Derpanis,
Kostas Daniilidis
Computer Vision and Pattern Recognition (CVPR), 2017 (Spotlight Presentation)
project page
/
supplementary
/
video
/
training code
/
demo code
/
bibtex
@inproceedings{pavlakos2017volumetric,
Author = {Pavlakos, Georgios and Zhou, Xiaowei and Derpanis, Konstantinos G and Daniilidis, Kostas},
Title = {Coarse-to-Fine Volumetric Prediction for Single-Image 3{D} Human Pose},
Booktitle = {CVPR},
Year = {2017}}
For any questions regarding this work, please contact the corresponding author at pavlakos@seas.upenn.edu